
Uipath üzerinde geliştirme yapmak her ne kadar kolay ve basit olsa da bazen karşımıza çıkan süreçler bizi tasarım ve yönetim açısından zorlayabiliyor. Özellikle “bulk data” diye adlandırılan, çok sayıda veriyi işlememiz gereken ve çalışması oldukça fazla zaman alan süreçlerde farklı bir yapı kullanma ihtiyacı doğuyor. Böyle durumlarda kullanmamız gereken yapı aslında Uipath tarafından geliştirilmiş ve bizlere sunulmuş. Orchestrator arayüzünde bulunan kuyruk(queue) yapısını, “bulk data” lı süreçler için ihtiyacımız olan ve kullanmamız gereken bir araç olarak görebiliriz. Kuyruk yapısını kullanmak için “dispatcher” ve “performer” diye adlandırdığımız iki farklı proje geliştirmemiz gerekiyor. Yani tek bir sürecin iki farklı sürece bölünmesi gibi düşünebiliriz. Bu durumda, sürecin dispathcher ayağı kuyruğa veri atan kısmı; performer ayağı ise yine aynı kuyruktan verileri alıp işleyen kısım olarak rol almış oluyor.
Peki verileri kuyruğa atıp tekrar kuyruktan çekerek işlemek bize ne kazandırıyor? Aslında bu yapıyı kullanmanın temel amacı büyük sayıda veriye sahip olan süreçlerin birden fazla robotta çalışmasını sağlamak. Yani; çalışması uzun süre alan bir sürecin tek bir robotta çalışmasındansa, aynı anda x adet robotta çalıştırıp verileri x kat daha az sürede işleyebilmemize olanak sağlamış oluyoruz. Bir anlamda iş yükünü bölüştürüyoruz gibi de düşünebiliriz. Bunun dışında verileri kuyruğa atmanın bir diğer avantajı da yine Orchestrator üzerinde, işlenen verilerin sayısal olarak kaç tanesinin başarılı çalıştığını, kaç tanesinin iş kuralı hatası veya sistem hatası aldığını da kolayca görebiliyor olmamız. Hatta verilerin detaylı içeriklerini de görme şansımız oluyor.
Yukarda da bahsettiğim gibi kuyruk yapısını kullanırken elimizde iki farklı süreç oluyor. Önce dispatcher kısmının olduğu robotu çalıştırıp verileri kuyruğa atmak ve daha sonra da performer kısmında çalışacak olan robotları tetiklemek gerekiyor. Öyle ki; performer kısmında çalışacak olan robotların tetiklenmesini, daha doğrusu hangi robotların tetikleneceğini dispatcher kısmına ekleyeceğimiz aktivitelerle de belirleyebiliriz. Böylece daha otomatize bir yapı oluşturmuş oluruz.
Bütün bu anlattıklarımı bir de geliştirmesini yaptığım çok sayıda veriye sahip bir süreçten örnekler vererek desteklemek istiyorum. Bu süreçte haftalık 30.000 adet veri geliyor ve 1 adet verinin işlenmesi ortalama 30 saniye sürüyor. Bu durumda 1 robot, tüm gün aralıksız çalışsa bile yaklaşık 3.000 adet veriyi işleyebiliyor. Bu yüzden süreci kuyruklu yapıyla geliştirdim ve dispatcher tarafında da kaç adet robotun kaç adet veriyi işleyebileceğiyle alakalı konfigüratif bir yapı oluşturdum.

Bu yapı sayesinde, yukarıdaki gibi bir config dosyasından kaç robotun çalışacağını(Max Robot), kaç tane verinin çalışacağını(Max Data) ve bir robotun kaç tane veriyi işleyeceğini(Job Limit) yönetebiliyoruz. Bunun dışında performer kısmında tetiklenecek olan iş ve ortam bilgisi de bu dosyada yer alıyor(Start Job sütunu). Bunu yaparken Orchestrator tarafında bir Environment açıp içinde hangi robotların olacağını belirlememiz gerekiyor ve o robotlardan hangisi müsaitse çalışmaya başlıyor; müsait olmayanlar ise “pending” durumuna geçiyor.

Yukardaki kod bloğunda verilerin kuyruğa atılması işlemini gerçekleştiren aktiviteler yer alıyor. Verilerin bir anda kuyruğa atılması zaman ve hafıza açısından yarattığı için, parçalara bölünmüş şekilde atmak daha sağlıklı oluyor. Bu yüzden her 2000 veride bir kuyruğa atma aktivitesi çalışıyor.



Daha sonra ”Get Jobs” aktivitesi sayesinde, Orchestrator’dan verilen environment üzerinde çalışır durumda olan robotların sayısı alınıyor. Bu bilgi birazdan tetiklenecek olan robot sayısını belirlemede kullanılacak.


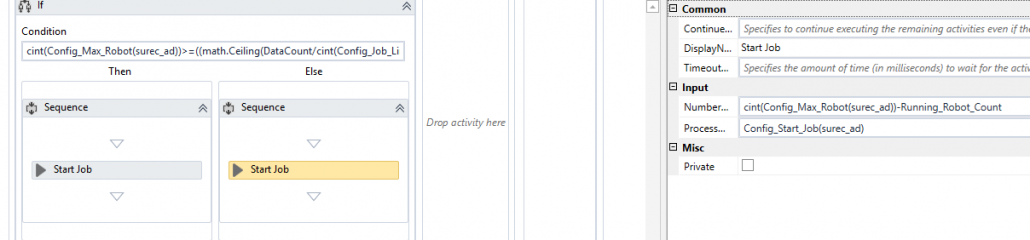
Bu kod bloğunda ise önce config doyasından alınan parametrelerin boş olup olmadığı ve hazırda çalışabilecek olan robotların varlığı gibi bilgiler kontrol ediliyor. Eğer gerekli koşullar sağlanıyorsa ikinci if bloğunda da kaç adet robotun tetikleneceğini belirlemek için config dosyasından alınan “max_robot” bilgisi ile Orchestrator üzerinde çalışır durumda olan robotların karşılaştırılması yapılarak “Start Job” aktivitesi sayesinde doğru sayıda robotun tetiklenmesi sağlanmış oluyor. Bu yapı sayesinde bize sadece sürecin dispatcher ayağını çalıştırmak ve config dosyasında gerekli parametreleri vermek kalıyor.